Are Algorithms Biased?
Algorithms reinforce human biases and stereotypes. This is dangerous.
June 27, 2020
After the end of the Second World War, the Nuremberg trials laid bare the atrocities conducted in medical research by the Nazis. In the aftermath of the trials, the medical sciences established a set of rules — The Nuremberg Code — to control future experiments involving human subjects. The Nuremberg Code has influenced medical codes of ethics around the world, as has the exposure of experiments that had failed to follow it even three decades later, such as the infamous Tuskegee syphilis experiment.
The direct negative impact of AI experiments and applications on users isn't quite as inhumane as that of the Tuskegee and Nazi experimentations, but in the face of an overwhelming and growing body of evidence of algorithms being biased against certain demographic cohorts, it is important that a dialogue takes place sooner or later. AI systems can be biased based on who builds them, the way they are developed, and how they're eventually deployed. This is known as algorithmic bias.
While the data sciences have not developed a Nuremberg Code of their own yet, the social implications of research in artificial intelligence are starting to be addressed in some curricula. But even as the debates are starting to sprout up, what is still lacking is a discipline-wide discussion to grapple with questions of how to tackle societal and historical inequities that are reinforced by AI algorithms.
We are flawed creatures. Every single decision we make involves a certain kind of bias. However, algorithms haven't proven to be much better. Ideally, we would want our algorithms to make better-informed decisions devoid of biases so as to ensure better social justice, i.e., equal opportunities for individuals and groups (such as minorities) within society to access resources, have their voices heard, and be represented in society.
When these algorithms do the job of amplifying racial, social and gender inequality, instead of alleviating it; it becomes necessary to take stock of the ethical ramifications and potential malevolence of the technology.
This essay was motivated by two flashpoints: the racial inequality discussion that is now raging on worldwide, and Yann LeCun's altercation with Timnit Gebru on Twitter which was caused due to a disagreement over a downsampled image of Barack Obama (left) that was depixelated to a picture of a white man (right) by a face upsampling machine learning (ML) model.
The (rather explosive) argument was sparked by a tweet by LeCun where he says that the resulting face was that of a white man due to a bias in data that trained the model. In simple terms, LeCun said that the results could be improved by increasing the number of black faces that the model sees. Gebru responded sharply that the harms of ML systems cannot be solely reduced to biased data.
In most baseline ML algorithms, the model fits better to the attributes or patterns that occur most frequently across various data points. For example, if you were to design an AI recruiting tool to review the résumés of applicants for a software engineering position, you would first need to train it with a dataset of past candidates which contains details like "experience", "qualifications", "degree(s) held", "past projects" etc. For every datapoint, the algorithm of the hiring tool would need a decision or a "label", so as to "learn" how to make a decision for a given applicant by observing patterns in their résumé.
For an industry where the gender disparity in representation is large, it is reasonable to assume that a large majority of the data points will be male applicants. And this collective imbalance in the data ends up being interpreted by the algorithm as a useful pattern in the data rather than undesirable noise which is to be ignored. Consequently, it teaches itself that male candidates are more preferable than female candidates.
I wish that this was merely an imaginary, exaggerated example that I used to prove my point. It is not.
LeCun wasn't wrong in his assessment because in the case of that specific model, training the model on a dataset that contains faces of black people (as opposed to one that contains mainly white faces) would not have given rise to an output as absurd as that.
The misunderstanding clearly seems to emanate from the interpretation of the word "bias" — which in any discussion about the social impact of ML/AI seems to get crushed under the burden of its own weight. As Sebastian Raschka puts it, "the term bias in ML is heavily overloaded". It has multiple senses that can all be mistaken for each other:
- bias (as in mathematical bias unit)
- Societal bias
- Inductive bias (which is dependent on decisions taken to build the model)
- bias-variance decomposition of a loss function
- Dataset bias
I imagine that a lot of gaps in communication could be covered by just being a little more precise when we use these terms. But the one upside to a public feud between a Turing Award winner and a pioneer of algorithmic fairness is that people in the community are bound to talk about it. This will hopefully mean an increased awareness among researchers about the social implications of their findings and with that, hopefully, an increased sense of responsibility to mitigate the harms.
Learning algorithms have inductive biases going beyond the biases in data too, sure. But if the data has a little bias, it is amplified by these systems, thereby causing high biases to be learnt by the model. Simply put, creating a 100% non-biased dataset is practically impossible. Any dataset picked by humans is cherry-picked and non-exhaustive. Our social cognitive biases result in inadvertent cherry-picking of data. This biased data, when fed to a data-variant model (a model whose decisions are heavily influenced by the data it sees) encodes these societal, racial, gender, cultural and political biases and bakes them into the ML model.
These problems are exacerbated, once they are applied to products. A couple of years ago, Jacky Alciné pointed out that the image recognition algorithms in Google Photos were classifying his black friends as "gorillas." Google apologised for the blunder and assured to resolve the issue. However, instead of coming up with a proper solution, it simply blocked the algorithm from identifying gorillas at all.
It might seem surprising that a company of Google's size was unable to come up with a solution to this. But this only goes to show that training an algorithm that is consistent and fair isn't an easy proposition, not least when it is not trained and tested on a diverse set of categories that represent various demographic cohorts of the population proportionately.
Problems of algorithmic bias are not limited to image/video tasks and they manifest themselves in language tasks too.
Language is always "situated", i.e., it depends on external references for its understanding and the receiver(s) must be in a position to resolve these references. This therefore means that the text used to train models carries latent information about the author and the situation, albeit to varying degrees.
Due to the situatedness of language, any language data set inevitably carries with it a demographic bias. For example, some speech to text transcription models tend to have higher error rates for African Americans, Arabs and South Asians as compared to Americans and Europeans. This is because the corpus that the speech recognition models are trained are dominated by utterances of people from western countries. This causes the system to be good at interpreting European and American accents but subpar at transcribing speech from other parts of the world.
Another example in this space is the gender biases in existing word embeddings (which are learned through a neural networks) that show females having a higher association with "less-cerebral" occupations while males tend to be associated with purportedly "more-cerebral" or higher paying occupations.
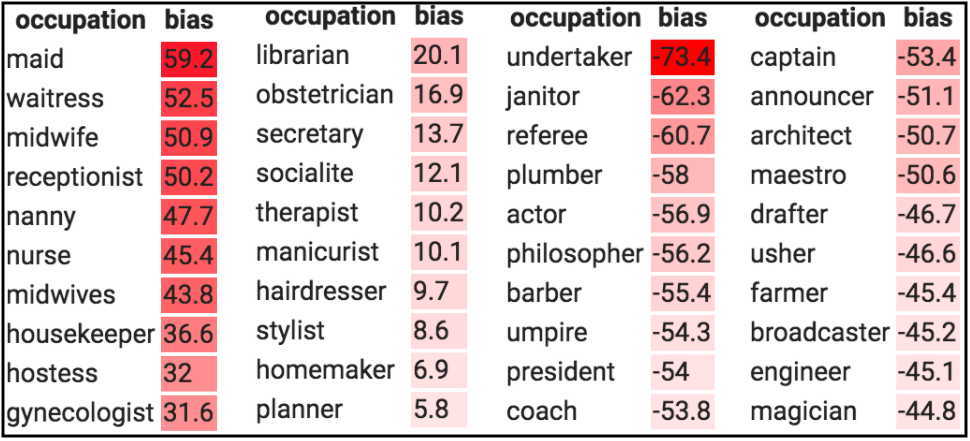
For ML Researchers it would be easy to punt the blame and absolve themselves of all responsibility, but it is imperative for them to acknowledge that they—knowingly or otherwise—build the base layer of AI products for a lot of companies that are devoid of AI expertise. These companies, without the knowledge of fine-tuning and tweaking models, use pre-trained models, as they are, put out on the internet by ML researchers (for e.g. - models like GloVe, BERT, ResNet, YOLO etc).
Deploying these models without explicitly recalibrating them to account for demographic differences can thus lead to issues of exclusion and overgeneralisation of people along the way. The buck stops with the researchers who must own up responsibility for the other side of the coin.
It is also easy to blame the data and not the algorithm. Pinning the blame on just the data is irresponsible and akin to saying that the racist child isn't racist because he was taught the racism by his racist father.
More than we need to improve the data, it is the algorithms that need to be made more robust, less sensitive and less prone to being biased by data that is skewed. This needs to be a responsibility for anyone who does research. In the meantime, de-bias the data.
The guiding question for deployment of algorithms in the real world should always be "would a false answer be worse than no answer?"
Thanks to Nayan K, Naga Karthik and Bina Praharaj for reviewing drafts of this.
References
- Buolamwini, J., Gebru, T. Gender Shades: Intersectional accuracy disparities in commercial gender classification. in Conference on Fairness, Accountability and Transparency, 2018.
- Facial Recognition Is Accurate, if You're a White Guy by Steve Lohr
- Krishnapriya, KS., et al. Characterizing the Variability in Face Recognition Accuracy Relative to Race in CVPR Workshops, 2019.
- Life of Language by Martin Kay, Stanford University
- Text Embedding Models Contain Bias. Here's Why That Matters. by Ben Packer et al., Google AI
- Bolukbasi, T., et al. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings in NeurIPS 2016.